The Framework
The decisions that sink an AI project are the ones you make early, before any code, and you usually don't feel them until production. This framework is built to get those decisions right the first time, and to rework the project when you hit issues anyway. I distilled it from my own years of AI work plus what I learned from others, and it applies to any project.
The framework is AI-agnostic. I teach it using traditional ML, GenAI, and now agentic AI.
The framework runs in three stages. The first is Frame: defining what the project is for before you build it. The second is Diagnose: figuring out what is actually failing once you have something in production. The third is Reframe: deciding whether to persist with the current approach, pivot to a different one, or stop the project entirely. If you decide to pivot, I provide a set of strategies for rethinking your approach.
There are a lot of decisions in the Frame stage. That is where GOATS comes in. It's an easy way to remember and cover the essential decisions for every AI project.
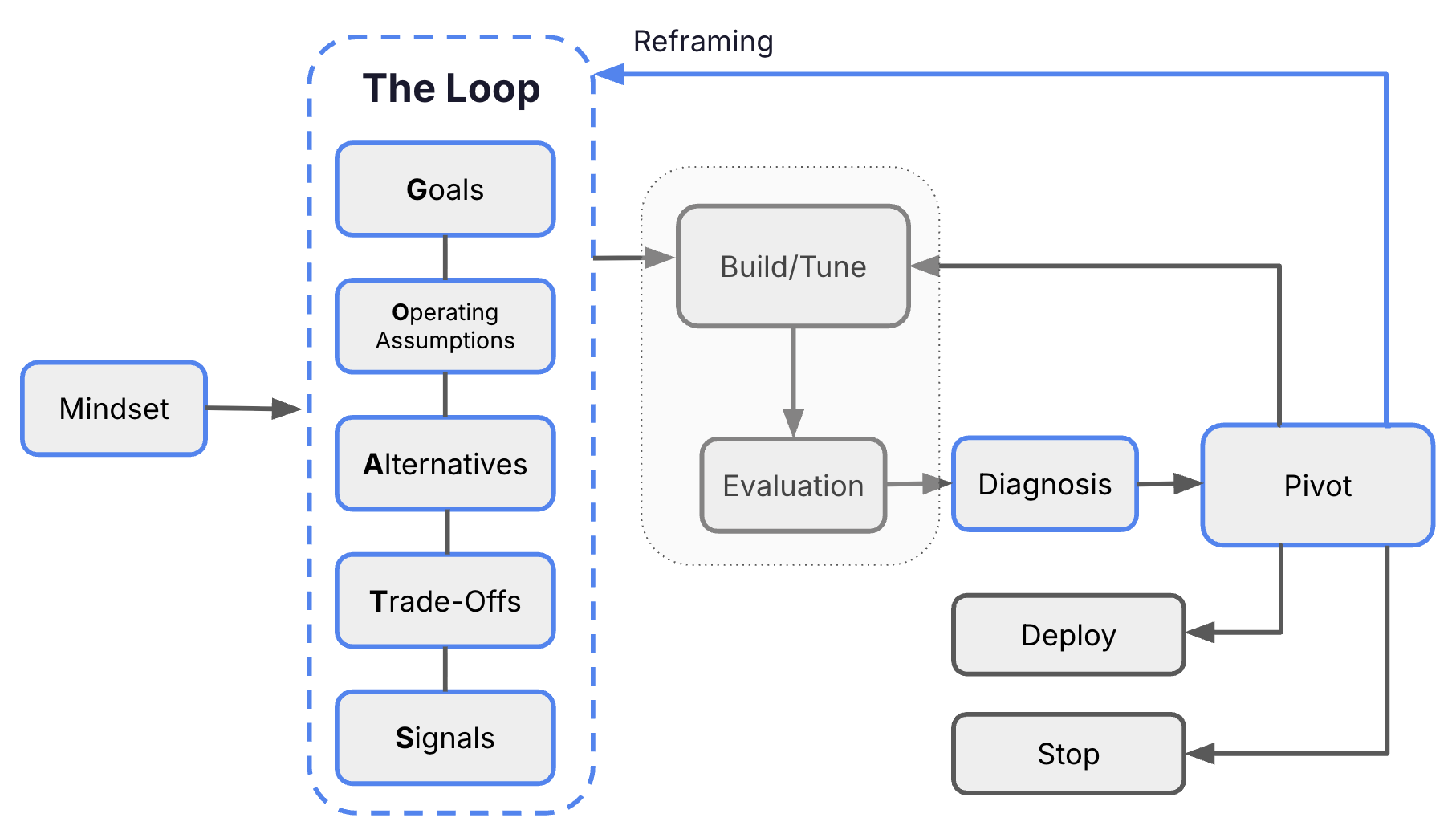
The whole framework on one page. The dashed box on the left is the GOATS loop. The dotted box in the middle is the build-evaluate-diagnose cycle. The reframing arrow on the right is what most framing material does not cover.
1. Frame
The first pass through the loop happens before you build. The tool is GOATS: Goal, Operating Assumptions, Alternatives, Trade-offs, Signals. Five steps that run in order. Each step constrains the next.
- Goal. What decision does the system support, and how will success get measured? I teach you to avoid vague goals like "predict churn" and chisel them into specific decisions that tie to a business outcome and a technical metric.
- Operating Assumptions. What would have to be true for the goal to be reachable, and what is the atomic unit the system decides about? A model that scores per customer-contract and a model that scores per customer-month are different products.
- Alternatives. What approaches could work? Ranking, classification, regression, rules, retrieval, an agent. Most teams skip this step and pick by reflex.
- Trade-offs. How do the alternatives compare on the dimensions that actually matter (latency, interpretability, cost, downstream workflow). Good projects stop and argue here. The arguments are cheaper than the wrong build.
- Signals. How will the team know if the project is working, failing, or drifting after launch? The signals are the dashboard, not the eval table. They are also what tells you when to run the loop again.
2. Diagnose
The second stage starts the day the project ships. Some of the signals from step five are noise. Some say the frame is breaking. Diagnostics is the work of telling which is which.
It is not the same as evaluation. Evaluation tells you the model is wrong. Diagnostics tells you which assumption is wrong, and whether the answer is "fix the model" or "change the frame." Tuning a model when the frame is wrong is the single most expensive mistake in AI work, and it stays expensive because nothing about it looks like a mistake while it is happening.
The course organizes diagnostics around three questions, in order. The same three questions work for traditional ML, GenAI, and agentic systems. The probes and tools inside each one are what change.
Is there signal?
Can the system actually solve this problem? Does information flow through it at all? A model with no signal in the data will look fine on the inner loop (precision, recall, retrieval accuracy) and produce nothing on the outer loop (user outcomes, business metric). The first diagnostic move is to confirm signal exists before spending another week on the model.
Is there cheating?
Is the score being achieved by routes that will not survive production? Data leakage, training-test contamination, reward hacking, prompt injection through retrieved documents, evaluation the model can see during training. Cheating is the failure mode where the eval looks great and the production result does not. The diagnostic move is to construct probes the model cannot game.
Is the metric real?
Does the metric track what you actually care about? The number you optimize and the number the business feels are often not the same. Take churn: if Customer Success can only call the top 100 accounts a week, what matters is getting that top 100 right (precision-at-100), not an overall balance across every prediction (F1). Optimize the wrong one and the model looks good while the business sees nothing.
The benchmark and the user experience can also measure completely different things. Galactica's benchmarks looked great. Users surfaced the failure in seventy-two hours. The move is to keep checking the metric still tracks the business outcome, and to wire in user-experience signals the moment the model-side number stops moving with what the business sees.
Metrics come in three layers. Model metrics (AUC, RMSE, retrieval accuracy) tell you the model works. Product metrics (revenue, retention, resolved tickets) tell you the business feels it. System metrics (latency, throughput, cost) tell you it is affordable to run. You can be green on all three and still be wrong. The number to watch is not any single layer. It is whether the model metric still moves the product metric. When the model metric climbs and the product metric sits flat, you optimized the wrong thing, and you miss it entirely if you only track one layer.
Diagnostics is the half of the course that product courses do not cover at all.
3. Reframe
The third stage is the decision: persist, pivot, or stop.
- Persist means the frame is right, the diagnostics found a fixable model problem, and the team should keep going.
- Pivot means the frame is wrong. The goal stays, but something below it changes: the atomic unit, the alternative architecture, the autonomy level, or the target.
- Stop means the project should not continue. Either the goal is unsupported by the business, no alternative inside the trade-off space is good enough, or the cost of running the system exceeds the value it produces.
Persist is comfortable. Stop is honest. Pivot is the hard move. It requires actually rerunning GOATS with new information and accepting that the first frame was wrong without throwing the work away.
Five reframing moves
When the decision is to pivot, the actual change usually takes one of five shapes.
- Retarget. Change the goal. The decision the system was supposed to support turns out to be the wrong one.
- Decompose. Change the atomic unit. Split a single hard decision into a sequence of smaller, more reliable ones.
- Ensemble. Change the architecture. Combine multiple weak signals or models that disagree well, instead of forcing a single model to carry the whole load.
- Constrain. Change the autonomy level. Replace open-ended generation with a structured output, or replace an autonomous agent with a guided pipeline.
- Simplify. Cut the scope. Reduce the surface area until what remains is reliable, then expand if and when the simpler version proves out.
A common pattern in agent work right now is constrain: teams pivot from a full autonomous agent to a constrained pipeline with three deterministic steps and one LLM call. In traditional ML the common move is ensemble: a marginal model gets rescued by combining it with others that disagree well.
Across ML, GenAI, and agents
The three stages are common across different types of AI problems. Each type requires different tactics inside them.
A team framing a churn-ranking system, a team framing a compliance RAG bot, and a team framing an autonomous research agent all run Frame, Diagnose, and Reframe. What changes is which alternatives are on the table, which signals fire when the frame breaks, and which reframing moves earn their keep. The course teaches the specific tactics for each class.
Traditional ML
In traditional ML the framing question is the shape of the problem. "Predict churn" could be classification, regression, or ranking, and the right shape depends on how the output gets used, not on the data. Get it wrong and everything downstream optimizes for the wrong thing.
Once it ships, the signals that the frame is breaking are ML-specific: data leakage, feature-importance shifts, and distribution drift. The usual reframing move is to ensemble a marginal model with others that disagree well, or to split one hard prediction into two stages, a classification head feeding a regression head, the way Tweedie-style insurance models survive zero-inflated targets.
The cohort worked project runs this on churn, where "predict churn" becomes a ranking problem because Customer Success can only call a fixed number of accounts a week.
GenAI
In GenAI the framing question is which architecture earns the LLM call. Does the answer need to be grounded in your documents (retrieval) or generated from the model's weights (generation)? Does the downstream need structured fields (extraction) or prose? The wrong call is what wires a generative model into a customer-facing path with nothing to anchor it.
The signals that the frame is breaking are hallucination, retrieval failure, and prompt injection through retrieved content. The reframing move is to switch from generation to retrieval so the model is grounded in your documents, add a schema-validated extraction layer (Outlines, Instructor, function calling) so the output is usable, or put a verifier model on top to catch what the generator cannot self-detect.
The cohort worked project runs this on compliance RAG, where retrieval and a confidence threshold beat an autonomous agent on accuracy, latency, and cost.
Agents
In agents the framing question is how much autonomy the LLM actually needs. The spectrum runs from rules to constrained output to guided agent to full agent, and the right point is usually the leftmost one that still solves the problem. Most teams reach for full autonomy first and pay for it.
The signals that the frame is breaking are looping, unbounded cost (the loop runs for days with no stop criterion), confident-but-wrong outputs the agent rates as correct, and handoffs that lose state. The reframing move is almost always to constrain: drop one step left, from full agent to guided agent to staged pipeline.
The cohort worked project runs this on an agent pivot, where a multi-step research agent becomes a staged pipeline with three deterministic steps and one LLM call. Faster, cheaper, debuggable, and shipped.
Why one framework covers all of it
This course focuses on the timeless principles for buildng effect AI projects. The five GOATS questions, the three diagnostic questions, and the persist/pivot/stop decision apply to a 2015 logistic regression and a 2026 multi-agent system.